
Houston, We Have a Data Problem
Genomics is generating the most consequential dataset in history. The gap between generating it and having a vision for it will define the next era of human health, wealth, and power.


Last week the BioIndustry Association, the UK’s life sciences trade body, published a ten-year vision for turning the country’s genomic and health data into a coordinated national economic asset, building on the £600 million Health Data Research Service the government committed to in April 2025. The framing was explicit, genomic data is national infrastructure, the same way roads and power grids are infrastructure, and the country that coordinates it best will compound advantages in AI-enabled medicine for decades. So far, the United States has not made a similar commitment.
The US has the data, and an extraordinary opportunity. What it seemingly does not have is a strategy for what the data is for, who coordinates it, or who it ultimately serves and how.
An enormous amount of genomic information is being generated right now, through clinical genetic testing, hospital biobanks, research programs, and consumer DNA companies, accumulating across systems that do not talk to each other, governed by rules that were not designed together, held by institutions with fundamentally different definitions of what they are even holding. Two major genetic testing companies went bankrupt in the past two years. When 23andMe filed in March 2025, Regeneron Pharmaceuticals had an initial purchase agreement for 15 million customers’ genetic records at $256 million, and 27 states filed privacy objections with the bankruptcy court, arguing genetic data is not ordinary bankruptcy property. The bidding reopened, Anne Wojcicki created a nonprofit specifically to reacquire the assets, and TTAM won at $305 million with court approval in June 2025. Throughout the entire proceeding, HIPAA did not apply, because direct-to-consumer genetic companies are exempt, meaning those 15 million records had less legal protection than a pharmacy prescription. GlaxoSmithKline had licensed 23andMe data for drug development beginning in 2018. The bankruptcy made visible what had been happening for years. Invitae’s genetic data went to Labcorp in 2024, framed as an opportunity to utilize genetic data for clinical trials, without equivalent legal challenge or court-appointed privacy oversight, and it transferred quietly.
I have been building an ecosystem intelligence framework around genomic variant populations for the past six months, analyzing structural relationships, capital flows, and institutional gaps across this space, and one of the things that kind of work makes visible is that fragmentation at the data level produces predictable gaps everywhere downstream, and those gaps are not random, they follow the data.
Part of what makes the dataset so difficult to reason about is that the categories are inconsistent and unstable. Germline variants like BRCA1 live in one institutional infrastructure, somatic variants like JAK2 in another, neurological susceptibility variants like APOE4 in yet another, and none of these systems talk to each other. Variants of uncertain significance are reclassified constantly, but reclassifications often live in research databases rather than patient records, meaning the person tested three years ago when something was a VUS may now carry a pathogenic variant by current classification and have no idea. I recently had my own medical records disappear entirely from one of the country’s leading institutions following a system migration, not reclassified, not updated, simply gone.
In building population estimates across actionable genomic categories, I have repeatedly run into the same problem: the population is almost certainly large, but the underlying data is too fragmented to support a defensible single number. A 2025 JAMA study found that roughly one in twenty U.S. adults carries a pathogenic or likely pathogenic germline variant in a cancer susceptibility gene, covering cancer susceptibility genes only, before cardiovascular, neurological, pharmacogenomic, somatic, and reproductive categories are added. The real number is almost certainly much larger. AI built on top of fragmented, inconsistently labeled, actively reclassifying data may not produce more reliable medicine. It may produce more confident uncertainty at scale. The National Security Commission on Emerging Biotechnology said this in their 2025 report: fragmented biodata is not a healthcare inefficiency. It is a structural weakness in an era when AI-enabled biology is a domain of genuine geopolitical competition.
The countries moving fastest are organizing around three distinct models.
The state-commercial model is China’s. A $9.2 billion, 14-year Precision Medicine Initiative launched in 2016 with a goal of sequencing more than 100 million genomes by 2030, executed through the government-backed BGI, which accounts for roughly half of global genetic sequencing capacity, with MGI having driven whole genome sequencing costs to under $100. BGI has delivered more than 30 million screenings through public health programs and this month hosted the 2026 ISBER Global Biobanking Congress in Shenzhen, positioning itself to set international biobanking standards. That is not a company strategy, it is a national strategy wearing a company’s name. According to IQVIA’s Global R&D Trends 2026, China now leads globally in Phase I clinical trial activity. Meanwhile, Altos Labs has published a research collaboration with BGI in Nature, analyzing 387,000 cells from aging human skeletal muscle. American longevity capital is working with Chinese national genomics infrastructure on the core biology of aging while Washington passes regulations designed to keep China out of American genomic data. Those regulations and that science are not talking to each other.
The public coordination model is what the UK, France, Denmark, Singapore, and Switzerland are building. The UK has the NHS, a single-payer system that generates population-scale longitudinal health records linked by a unified patient identifier, the structural foundation that makes a national data strategy possible. UK Biobank recruited 503,317 participants between 2006 and 2010, and in February 2026 GP patient records were added for the first time, effectively doubling recorded cases of conditions including dementia, depression, and heart failure. France invested €239 million in PFMG2025, building 12 ultra-high-throughput sequencing centers. Denmark established a National Genome Centre in 2019 with $144 million in Novo Nordisk Foundation funding, returning sequencing results to doctors as part of standard clinical care. A January 2025 Lancet paper identified the UK, Sweden, and Denmark as the only three countries to have achieved genuine clinical integration of genomic medicine. Singapore and Switzerland are building coordinated national AI-genomics platforms targeting populations of up to one million.
The population-specific model is what Israel and Qatar are building. Israel’s four national health plans function as both insurers and care organizations, giving the country the same structural data advantage the UK has through the NHS. Clalit’s Psifas project has already linked close to 50,000 genomic samples to more than 20 years of medical records, and MIT is launching an AI breast cancer screening system through Clalit in 2026, the first of its kind anywhere in the world. Qatar is sequencing Arab genomes specifically because they are not in Western databases, filling a gap nobody else was filling.
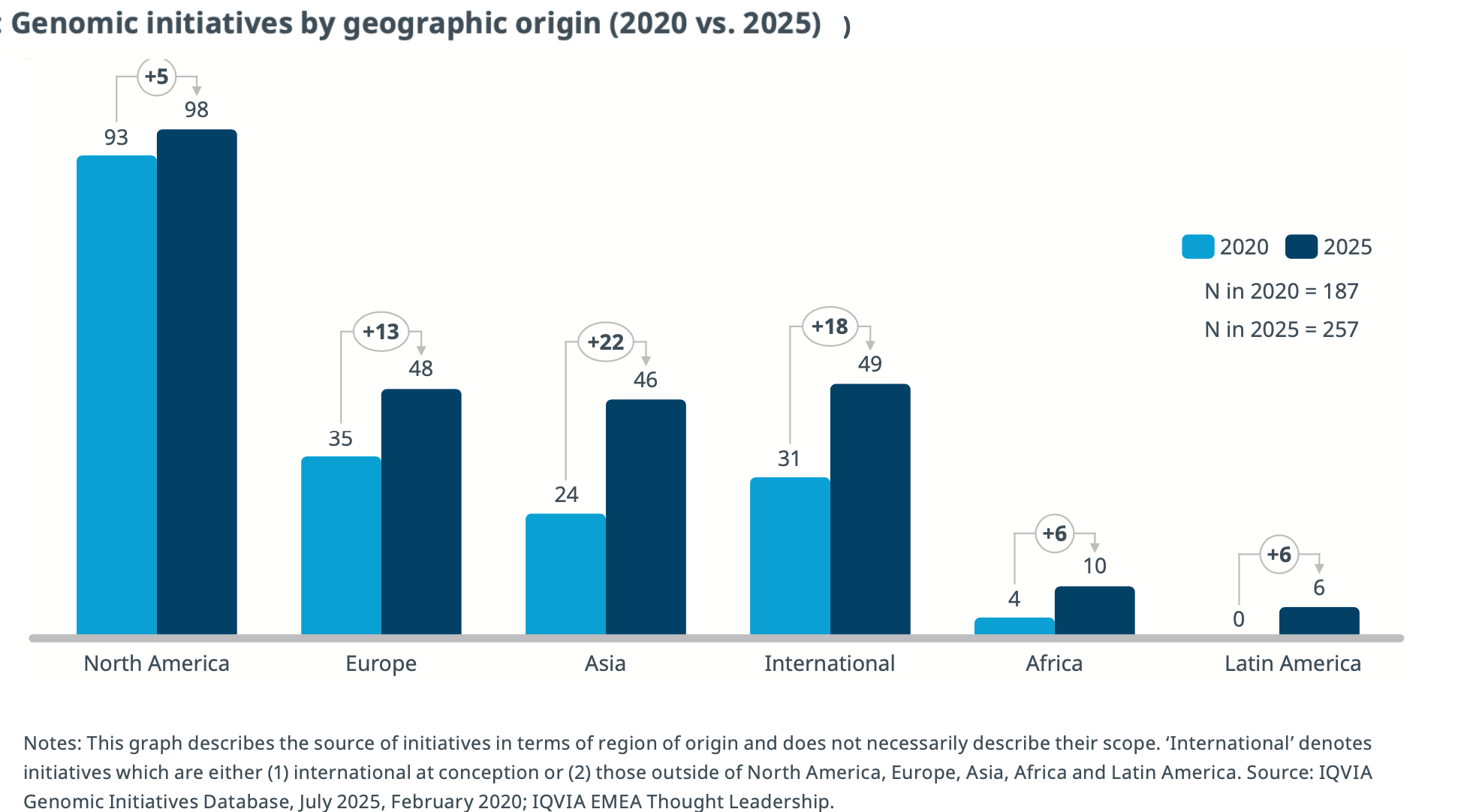
Between 2020 and 2025, Asia’s genomic initiatives grew by 92 percent. North America’s grew by 5 percent. The IQVIA Genomic Initiatives Database now counts 257 active initiatives globally, up from 187 in 2020. The United States has more data than any of them and less of a plan than most.
The US’s National Human Genome Research Institute maintained a 15-year public newsletter tracking global genomics developments, lost its director and much of its communications infrastructure in 2025 as part of a broader wave of federal science changes. Its former director is now Chief Medical Officer at Illumina, the company that makes the sequencing machines powering genomic research worldwide and that China banned from its market in March 2025 as part of its strategy to build sequencing independence. The coordination function that once lived in the public sector appears to have moved to private capital, without a clear replacement.
Private investment in longevity science more than doubled in 2025, hitting $8.49 billion across 325 deals, flowing into DNA repair, genome stability, and aging biology, the same mechanisms the public infrastructure was supposed to be tracking. IQVIA’s Global R&D Trends 2026 identifies coordinated real-world evidence as a primary solution to trial enrollment inefficiency, which has grown to a median of more than 16 months. Organized genomic data from characterized populations is precisely what that looks like in practice.
The people who have actually solved the data coordination problem are the ultra-wealthy, through concierge medicine and longevity programs, and their solution, even on top of all the AI, devices, and monitoring technologies, is a human being, a dedicated curator whose job is to maintain a coherent, updated picture of one person’s biological signals across every system and every reclassification. Not AI, not interoperability standards, but humans. The longevity community did not wait for the infrastructure problem to be solved. They hired around it. When the most medically sophisticated people in the world arrive at human curation as the answer to a problem that AI hasn’t solved, the gap is real and it is large.
Solving it may be the largest untapped opportunity of the next century.